Vectorization: a super-fast alternative to loops in Python
Feb. 05
6min read
Introduction
Loops are a fundamental concept in programming and one that is traditional at that, found across various languages. They're our go-to defacto for repetitive tasks or running across data structures such as sets, lists, dictionaries, arrays and even generators , but when dealing with massive datasets, relying on loops can be inefficient and time-consuming.
This is where the power of Vectorization in Python shines 👊.
Now what is vectorization and this strange but seemingly interesting word,
What is Vectorization?
Now, Vectorization involves executing array operations (commonly in NumPy) on entire datasets simultaneously. Unlike traditional loops, which handle one element at a time, Vectorization processes all elements in one swift operation.
Notice: Its is adviasable to use Vectorization for large or heavy task because it involves importing certain libaries native to data science and this can include but not limited to numpy, pandas , scikit and etc
In this story, we'll explore scenarios where replacing Python loops with Vectorization enhances efficiency, saving valuable time and boosting coding proficiency.
Example 1: Finding the Sum of numbers
Comparing Speed of finding the sum of large number in a data set using traditonal loops vs vectorization
Now let's look at a fundamental example of finding the sum of numbers using loops and Vectorization in Python.
Using Loops
import time
start = time.time()
# iterative sum
total = 0
# iterating through 1.5 Million numbers
for item in range(0, 1500000):
total = total + item
print('sum is:' + str(total))
end = time.time()
print(end - start)
#1124999250000
#0.14 Seconds
Using Vectorization
import numpy as np
start = time.time()
# vectorized sum - using numpy for vectorization# np.arange create the sequence of numbers from 0 to 1499999print(np.sum(np.arange(1500000)))
end = time.time()
print(end - start)
##1124999250000##0.008 Seconds
Vectorization took ~18x less time to execute as compared to the iteration using the range function. This difference will become more significant while working with Pandas DataFrame.
Example 2: Mathematical Operations (on DataFrame)
In Data Science, while working with Pandas DataFrame, developers use loops to create new derived columns using mathematical operations.
In the following example, we can see how easily the loops can be replaced with Vectorization for such use cases.
Creating the DataFrame
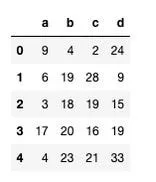
The DataFrame is tabular data in the form of rows and columns.
We are creating a pandas DataFrame having 5 Million rows and 4 columns filled with random values between 0 and 50. This compares much to matrix in mathematics , here a data frame is an a rectangular array of numbers havign a distribution of rows and columns
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 50, size=(5000000, 4)), columns=('a','b','c','d'))
df.shape.
# (5000000, 5) tells us the shape or dimension of the dataframe in terms of rows and cols
df.head(). # go to the first row
Snapshot of the top 5 rows (Image by Author)
We will create a new column ‘ratio’ to find the ratio of the column ‘d’ and ‘c’.
Using Loops
import timestart= time.time() #start timer
# Iterating or Looping through DataFrame usingfor-loop iterrows
for idx, rowin df.iterrows():
# creating a newcolumn
df.at[idx,'ratio'] =100* (row["d"] /row["c"])
end= time.time() #end timer
print(end-start) #preach time difference ortime taken
### 109 Seconds -> results
We can see a significant improvement with DataFrame, the time taken by the Vectorization operation is almost 1000x faster as compared to the loops in Python.
Example 3: If-else Statements (on DataFrame)
We implement a lot of operations that require us to use the ‘If-else’ type of logic. We can easily replace these logics with Vectorization operations in Python.
Let’s look at the following example to understand it better (we will be using the DataFrame that we created in use case 2):
Imagine we want to create a new column ‘e’ based on some conditions on the exiting column ‘a’.
Using Loops
import time
start = time.time()
# Iterating through DataFrame using iterrows
for idx, row in df.iterrows():
if row.a == 0:
df.at[idx,'e'] = row.d
elif (row.a <= 25) & (row.a > 0):
df.at[idx,'e'] = (row.b)-(row.c)
else:
df.at[idx,'e'] = row.b + row.c
end = time.time()
print(end - start)
### Time taken: 177 seconds
The time taken by the Vectorization operation is 600x faster as compared to the Python loops with if-else statements.
Example 4 (Advance): Solving Machine Learning/Deep Learning Networks
Deep Learning requires us to solve multiple complex equations and that too for millions and billions of rows. Running loops in Python to solve these equations is very slow and Vectorization is the optimal solution.
For example, to calculate the value of y for millions of rows in the following equation of multi-linear regression:
Linear Regression (Image by Author)
we can replace loops with Vectorization.
The values of m1,m2,m3… are determined by solving the above equation using millions of values corresponding to x1,x2,x3… (for simplicity, we will just look at a simple multiplication step)
Creating the Data
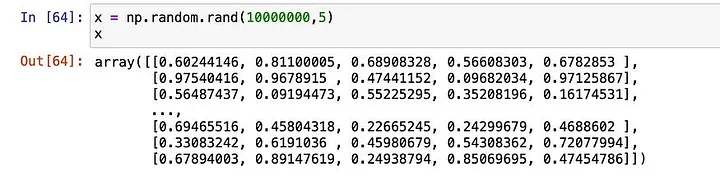
import numpy as np# setting initial values of m m = np.random.rand(1,5)# input values for 5 million rowsx = np.random.rand(5000000,5)
Output of m (Image by Author)Output of x (Image by Author)
Using Loops
import numpy as np
m = np.random.rand(1,5)
x = np.random.rand(5000000,5)
total = 0
tic = time.process_time()
for i inrange(0,5000000):
total = 0for j inrange(0,5):
total = total + x[i][j]*m[0][j]
zer[i] = total
toc = time.process_time()
print ("Computation time = " + str((toc - tic)) + "seconds")
####Computation time = 28.228 seconds